SQL 表也能做 LLM 质量评估?Dingo 2.0 支持多字段语义质检

告别繁琐配置,拥抱智能评估!Dingo 2.0.0 正式支持对传统关系型数据库(如 PostgreSQL、MySQL、Doris)中的 SQL 表进行原生、多字段的智能质量评估!
你没看错——现在,你的数据库表可以直接接受大语言模型(LLM)的“质检面试”。 无论是训练 SFT 数据中的 prompt-response 对,还是日常企业业务结构化数据,,只要它们存储在 SQL 表中,Dingo 就能:
- 自动连接数据库,
- 提取指定字段,
- 调用 LLM(如 GPT、Gemini 或本地 Qwen),
- 对数据进行语义级质量判断:回答是否完整?是否文不对题?是否存在幻觉?
这不仅是对数据源支持的扩展,更是将 LLM 原生评估能力下沉到数据源头的关键一步。 从此,高质量 AI 训练数据的保障,不再局限于文件或管道——它就在你的数据库里,实时、智能、可追溯。
Dingo 2.0.0 让每一行 SQL 数据都能被“理解”,而不仅仅是被“读取”。
Dingo 是一个完全开源的项目(Apache 2.0 License):
Discord / WeChat 社区: 加入我们的社区,一起讨论、提需求、贡献代码!
一、为什么我们需要这个功能?
在 AI 时代,数据是燃料,而数据质量就是引擎的润滑剂。无论是训练大模型、构建 RAG 应用,还是运行企业级智能 SaaS 系统,高质量的数据都是基石。
然而,在实际工作中,我们发现:
- 数据孤岛问题严重:很多核心数据仍然沉淀在 PostgreSQL、MySQL、Doris 等传统数据库中。
- 评估效率低下:传统的数据质量工具(如 Great Expectations)虽然强大,但其配置和使用方式更偏向于“数据管道”或“数据湖”,对于直接操作数据库表的场景,学习成本高、流程繁琐。
- 缺乏语义理解:许多工具只能做简单的空值、类型检查,无法理解“Prompt”和“Response”之间的逻辑关联,这对于 LLM 训练数据尤为重要。
一个典型的现实案例来自 Vimeo(全球领先的视频平台):
Vimeo 的 BI 团队每天从 Google、Facebook 等广告平台通过 Kafka 摄取大量数据,经 Airflow 处理后写入 Snowflake 数据仓库。他们曾多次遭遇上游服务中断或 Schema 变更,导致下游报表出现“静默错误”——数据缺失或陈旧,但数天都无人察觉,直到业务方投诉。
这说明:数据质量必须前置到数据源头,而不能依赖事后人工排查。Dingo 的这次更新,正是为了解决这些痛点——让数据工程师和 AI 工程师能像写 SQL 一样,直接对数据库表进行高效、智能、多维度的质量评估,真正实现“源头质检、智能洞察”。
二、与业界标杆的对比:Dingo 的独特定位
在介绍新功能前,让我们先看看 Dingo 是如何与两位行业巨头——Great Expectations (GX) 和 DQOps ——进行差异化对比情况如下表:
| 特性 | Great Expectations (GX) | DQOps | Dingo 2.0.0 |
|---|---|---|---|
| 核心定位 | “数据测试框架”,强调通过 Expectation 定义数据契约,适用于数据流水线(ETL/ELT)。 | “企业级数据质量平台”,提供完整的监控、告警、仪表盘,面向数据治理团队。 | “AI 原生数据质量工具”,专注于 LLM 训练数据、RAG 数据集的质量评估,同时向下兼容传统结构化数据。 |
| 使用场景 | 数据工程师在数据管道中嵌入单元测试。 | 数据治理专家对整个数据仓库进行持续监控。 | AI 工程师 & 数据工程师,快速评估单个数据集或数据库表的质量,尤其擅长处理“Prompt-Response”类数据。 |
| 上手难度 | 需要理解 Data Context, Expectation Suite 等概念,配置文件较复杂。 |
功能强大但界面和配置相对厚重,适合大型组织。 | 极简主义。直接通过 Python SDK 或 CLI,几行代码即可完成连接和评估。 |
| 多字段关联检查 | 支持,但需要编写复杂的 Expectation 逻辑。 | 支持,通过 YAML 配置定义规则。 | 内置丰富规则 + LLM 智能评估。例如,可轻松检查“Response 是否回答了 Prompt”,这是 GX 和 DQOps 难以优雅实现的。 |
| 数据库支持 | 通过 SQLAlchemy 连接,但主要作为数据源,而非核心评估对象。 |
核心功能,支持多种数据库,但更侧重于监控而非一次性评估。 | 原生支持。将数据库表直接映射为 SqlDataset,无缝接入现有评估体系。 |
总结来说:
- GX 是“数据契约”的缔造者,适合构建稳健的数据管道。
- DQOps 是“数据健康”的守护者,适合企业级数据治理。
- Dingo 则是“AI 数据”的质检员,它最懂 AI 工程师的需求,能用最简单的方式,解决最核心的问题——确保你的训练数据是干净、有效、安全的。
三、Dingo 的核心亮点:让多字段检查变得前所未有的简单
1. 架构示意图
为了帮助大家更好地理解 Dingo 支持多字段质检的工作原理,我们绘制了如下示意图:
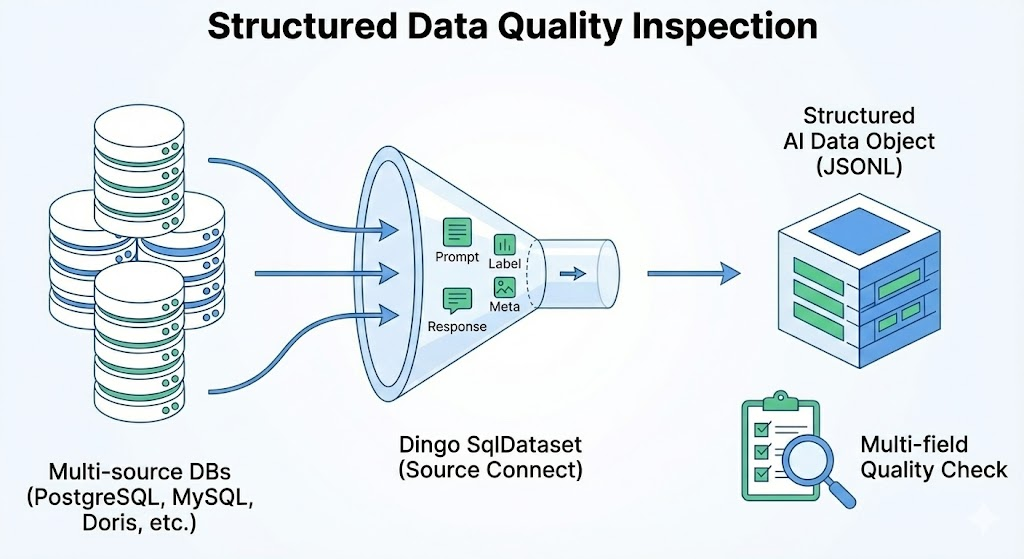
模块介绍:
- 数据源:左侧的数据库图标代表 PostgreSQL、MySQL、Doris 等多种数据源。
- 数据连接:中间的漏斗代表 Dingo SqlDataset,它负责建立与数据库的直接连接,并抽取字段(如 Prompt, Label, Response)。
- 数据对象:右侧的立方体代表转换后的结构化 AI 数据对象(JSONL 格式),这是 Dingo 内部处理的标准格式。
- 质量检查:下方的放大镜和清单图标代表“多字段质量检查”,这里会应用内置规则和 LLM 模型,对数据进行全方位评估。
2. 一行代码连接数据库,无需导出
Dingo 引入了全新的 SqlDataset 概念,让你可以直接从数据库读取数据。
from dingo.config import DatasetArgs, DatasetSqlArgs, InputArgs
from dingo.data.dataset.sql import SqlDataset
from dingo.data.datasource.sql import SqlDataSource
# 配置 SQLite 连接
sql_config = DatasetSqlArgs(
dialect="sqlite",
database="test.db"
)
# 配置数据集
dataset_config = DatasetArgs(
source="sql",
format="jsonl", # SQL 每行数据使用 jsonl 格式
sql_config=sql_config
)
3. 内置丰富规则,覆盖多维度质量
Dingo 不仅支持基础的空值、重复、格式检查,更提供了针对 AI 数据的高级规则:
- 语义相关性检查:检查 response 是否与 prompt 相关。
- 事实性核查:利用 LLM 判断 response 中是否存在事实性错误。
- 安全性评估:检测内容是否包含敏感信息或有害言论。
- 幻觉检测 (Hallucination):识别 response 中虚构的信息。
这些规则可以组合使用,形成一套完整的质量评估方案。
4. LLM 驱动的智能评估,超越传统规则
这是 Dingo 最大的杀手锏!对于复杂的语义判断,Dingo 可以调用 GPT-4o、Kimi 等大模型进行评估。
llm_config = {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
# 创建 InputArgs
input_args = InputArgs(
task_name="sql_eval",
input_path=sql_query, # SQL 查询放在 input_path
output_path="outputs/",
dataset=dataset_config,
evaluator=[
{
"fields": {"content": "title"}, # 指定要评估的数据库字段
"evals": [
{"name": "LLMTextWordStick", "config": llm_config}
]
},
{
"fields": {"content": "abstract"}, # 指定要评估的数据库字段
"evals": [
{"name": "LLMTextRepeat", "config": llm_config}
]
}
]
)
想象一下,你不再需要自己编写复杂的正则表达式或 SQL 语句来判断一条记录的好坏,而是交给 AI 来做“主观判断”。这极大地提升了评估的准确性和覆盖面。
四、实战案例:如何用 Dingo 检查一个 MySQL 训练数据表?
假设你有一个名为 sft_training 的 MySQL 表,包含 prompt, response, label 三个字段。你想检查这批数据的质量。
Step 1: 安装 Dingo
pip install dingo-python
Step 2: 编写评估脚本
# evaluate_mysql.py
from dingo.config import InputArgs
from dingo.exec import Executor
from dingo.dataset.sql import SqlDataset
# 1. 配置数据库连接
sql_config = DatasetSqlArgs(
dialect="sqlite",
driver="", # SQLite 不需要驱动
username="", # SQLite 不需要用户名
password="", # SQLite 不需要密码
host="", # SQLite 不需要主机
port="",
database="test.db" # 数据库文件路径
)
# 2. 创建 Dataset
dataset_config = DatasetArgs(
source="sql",
format="jsonl", # SQL 每行数据使用 jsonl 格式
sql_config=sql_config
)
# 3. 配置评估参数
sql_query = "SELECT * FROM test_table"
llm_config = {
"model": "gpt-4o",
"key": "YOUR_API_KEY",
"api_url": "https://api.openai.com/v1/chat/completions"
}
input_args = InputArgs(
task_name="sql_eval",
input_path=sql_query, # SQL 查询放在 input_path
output_path="outputs/",
dataset=dataset_config,
evaluator=[
{
"fields": {"content": "title"}, # 指定要评估的数据库字段
"evals": [
{"name": "LLMTextWordStick", "config": llm_config}
]
},
{
"fields": {"content": "abstract"}, # 指定要评估的数据库字段
"evals": [
{"name": "LLMTextRepeat", "config": llm_config}
]
}
]
)
# 4. 执行评估
input_args = InputArgs(**input_data)
executor = Executor.exec_map["local"](input_args)
result = executor.execute()
# 5. 查看结果
print("Overall Score:", executor.get_summary()["score"])
print("Bad Records Count:", len(executor.get_bad_info_list()))
Step 3: 运行并查看报告
python evaluate_mysql.py
# 评估完成后,会生成一个 output 目录
python -m dingo.run.vsl --input outputs/xxxxxx/
打开浏览器,你就能看到一份精美的、包含图表和详细数据的报告,清晰地告诉你哪些数据需要清洗。
五、未来展望:Dingo 的无限可能
这只是开始!我们正在规划更多激动人心的功能:
- 支持 Agent 应用类质量评估,构建从数据到模型,应用一体化的质量评估。
- 提供更丰富的预设行业数据应用规则模板,覆盖更多行业场景。
六、加入我们,共建开源生态!
Dingo 是一个完全开源的项目(Apache 2.0 License),我们欢迎每一位开发者加入!
- GitHub: https://github.com/MigoXLab/dingo
- 在线 Demo: https://huggingface.co/spaces/DataEval/dingo
- Discord / WeChat 社区: 加入我们的社区,一起讨论、提需求、贡献代码!
如果你觉得 Dingo 很棒,请给我们一个 ⭐ Star!你的支持是我们前进的最大动力!如果你有任何疑问、建议或想分享你的使用案例,欢迎在评论区留言,或直接在 GitHub 上提交 Issue!