Submitted by yaful 137 Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling · 28 authors 65 2
Submitted by zhuhz22 82 Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation Tsinghua Machine Learning Group 2
Submitted by ZhaoweiWang 67 MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models NVIDIA 16 4
Submitted by HaoyiZhu 57 SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer NVIDIA 1
Submitted by DarkBluee 50 MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory · 17 authors 25 1
Submitted by seawolf2357 50 Darwin Family: MRI-Trust-Weighted Evolutionary Merging for Training-Free Scaling of Language-Model Reasoning FINAL_Bench 2
Submitted by JamesMile 42 Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems Xi'an Jiaotong University 14 2
Submitted by Mar2Ding 39 WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation Intern Large Models 371 2
Submitted by ZhaoweiWang 37 STALE: Can LLM Agents Know When Their Memories Are No Longer Valid? HKUST NLP Group 2
Submitted by tonghe90 35 Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video · 2 authors 78 1
Submitted by taofeng 27 RouteProfile: Elucidating the Design Space of LLM Profiles for Routing University of Illinois at Urbana-Champaign 6 2
Submitted by JiaaqiLiu 21 EvolveMem:Self-Evolving Memory Architecture via AutoResearch for LLM Agents · 7 authors 1
Submitted by danielgilo 20 Realiz3D: 3D Generation Made Photorealistic via Domain-Aware Learning AI at Meta 1
Submitted by taesiri 17 ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both · 4 authors 1
Submitted by qmang 17 FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale · 17 authors 21 1
Submitted by alsu-sagirova 16 Learning to Communicate Locally for Large-Scale Multi-Agent Pathfinding · 8 authors 3
Submitted by quanhaol 14 DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models · 10 authors 1
Submitted by LiamLian0727 14 IntentVLA: Short-Horizon Intent Modeling for Aliased Robot Manipulation DeepCybo 3 1
Submitted by IvanTang 13 VGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction Peking University 1
Submitted by xichenhku 13 PanoWorld: Towards Spatial Supersensing in 360^circ Panorama World Zhejiang University 1
Submitted by oliveryanzuolu 7 RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO MVP Lab 29 2
Submitted by JasonTTY 7 Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models Zhejiang University 69 1
Submitted by JingyeChen22 6 Does Synthetic Layered Design Data Benefit Layered Design Decomposition? HKUST 3 2
Submitted by AmirMohseni 6 CurveBench: A Benchmark for Exact Topological Reasoning over Nested Jordan Curves · 4 authors 1 1
Submitted by KomeijiForce 6 BOOKMARKS: Efficient Active Storyline Memory for Role-playing University of California at San Diego 4 1
Submitted by jzhuang 6 WildTableBench: Benchmarking Multimodal Foundation Models on Table Understanding In the Wild The University of Queensland 2 2
Submitted by taesiri 5 Learning to Build the Environment: Self-Evolving Reasoning RL via Verifiable Environment Synthesis · 6 authors
Submitted by young13579 5 PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution DeepSeek 1
Submitted by qian43 4 Sat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image Wuhan Univeristy 32 1
Submitted by shash42 4 FutureSim: Replaying World Events to Evaluate Adaptive Agents Max Planck Institute for Intelligent Systems 17 1
Submitted by hanlincs 4 PhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation University of North Carolina at Chapel Hill 7 2
Submitted by hanhan3344 4 Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning ByteDance 2
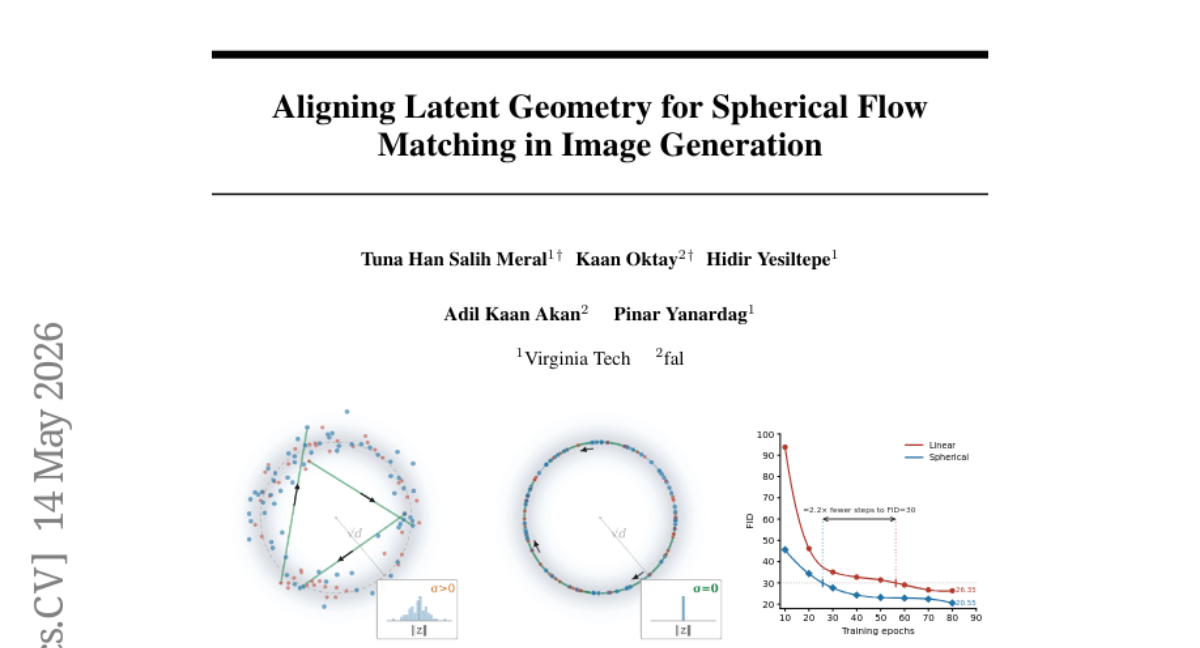
Submitted by tmeral 3 Aligning Latent Geometry for Spherical Flow Matching in Image Generation Virginia Tech 1
Submitted by n3il666 3 Topology-Preserving Neural Operator Learning via Hodge Decomposition Princeton University 2 1
Submitted by eternaldolphin 3 RewardHarness: Self-Evolving Agentic Post-Training Natural and Artificial Intelligence Lab 3 3
Submitted by SinclairSchneider 2 LLM-based Detection of Manipulative Political Narratives NLP Research Group UniBW 1 2
Submitted by SinclairSchneider 2 Ideology Prediction of German Political Texts NLP Research Group UniBW 1 1
Submitted by che111 2 Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation StepFun 1
Submitted by kaiyan289 1 Boosting Reinforcement Learning with Verifiable Rewards via Randomly Selected Few-Shot Guidance University of Illinois at Urbana-Champaign 0 1
Submitted by Julius-L 1 BEAM: Binary Expert Activation Masking for Dynamic Routing in MoE alibaba-inc 1
Submitted by Hanbo-Cheng 1 Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning University of Science and Technology of China 1
Submitted by taesiri 1 Quantitative Video World Model Evaluation for Geometric-Consistency · 5 authors 2
Submitted by DhavalPatel 1 SPIN: Structural LLM Planning via Iterative Navigation for Industrial Tasks IBM 1
Submitted by Sweson 1 PreScam: A Benchmark for Predicting Scam Progression from Early Conversations University of Notre Dame 1
Submitted by zhehuderek - Overcoming Dynamics-Blindness: Training-Free Pace-and-Path Correction for VLA Models · 9 authors 1


 yaful
yaful