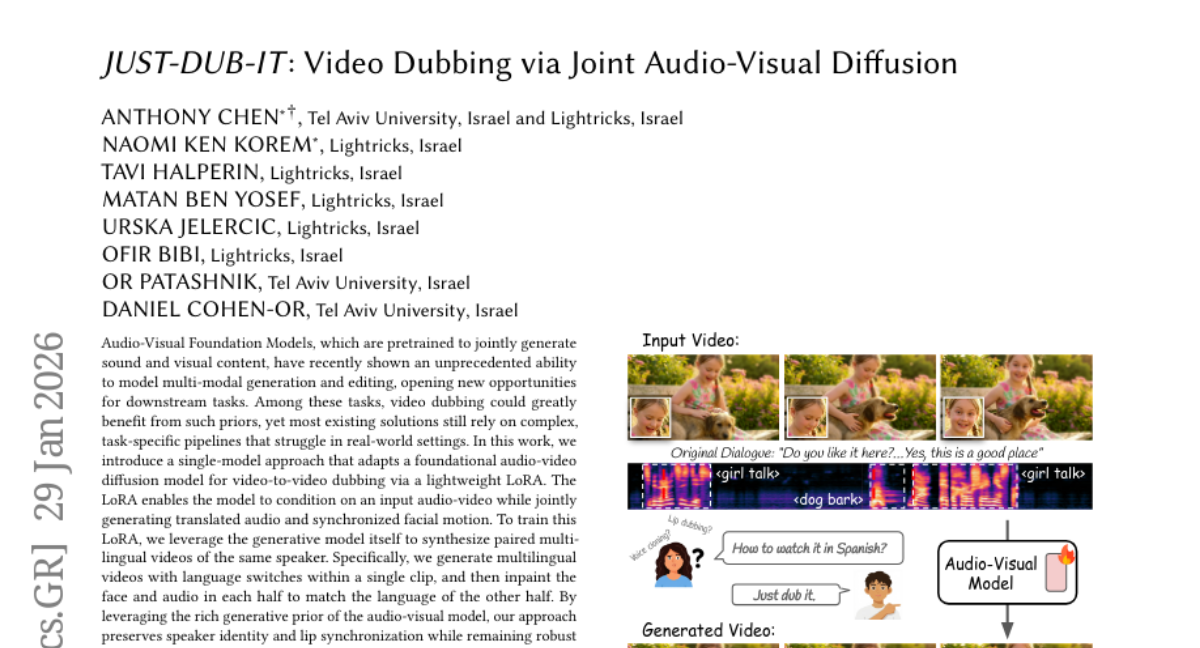
Submitted by Wendy-Fly 145 Idea2Story: An Automated Pipeline for Transforming Research Concepts into Complete Scientific Narratives AgentAlpha 266 2
Submitted by xiaochonglinghu 104 Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models alibaba-inc 97 3
Submitted by hzxie 60 DynamicVLA: A Vision-Language-Action Model for Dynamic Object Manipulation MMLab@NTU 78 3
Submitted by LHL3341 47 MMFineReason: Closing the Multimodal Reasoning Gap via Open Data-Centric Methods Shanghai Jiao Tong University 3
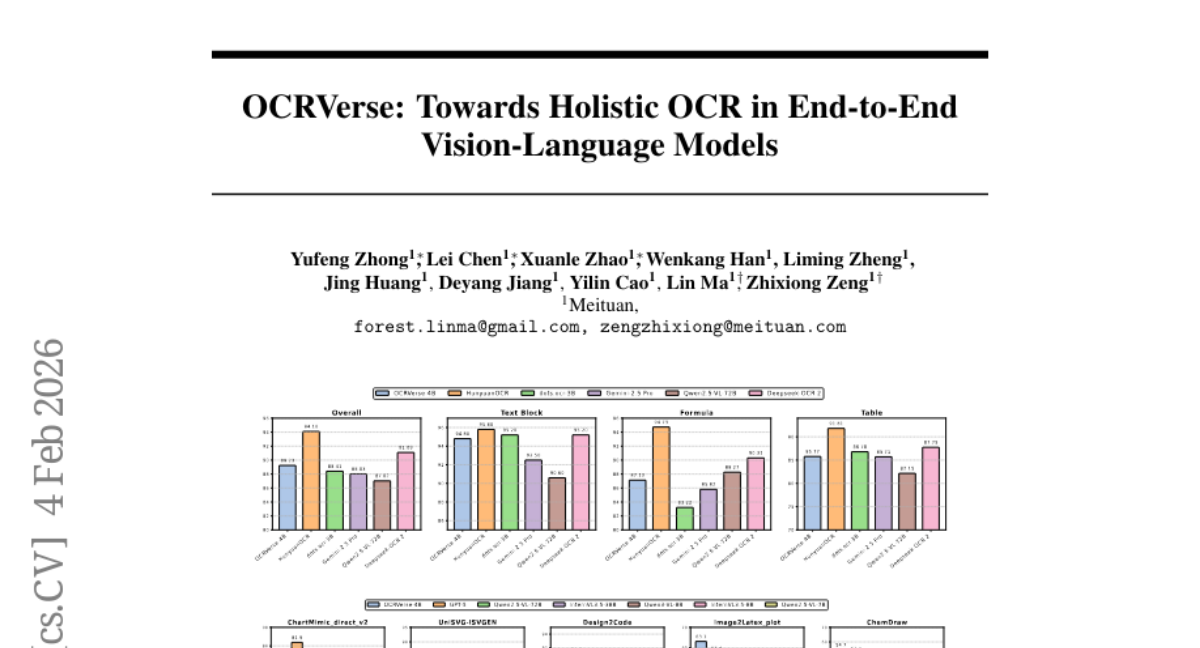
Submitted by xxxllz 42 OCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models · 10 authors 20 3
Submitted by FetchFortune 31 ConceptMoE: Adaptive Token-to-Concept Compression for Implicit Compute Allocation ByteDance Seed 13 3
Submitted by UML 20 PLANING: A Loosely Coupled Triangle-Gaussian Framework for Streaming 3D Reconstruction shanghai ailab 3
Submitted by SII-xrliu 18 AgentLongBench: A Controllable Long Benchmark For Long-Contexts Agents via Environment Rollouts OpenMOSS 4
Submitted by DiMaria0817 17 EEG Foundation Models: Progresses, Benchmarking, and Open Problems Huazhong University of Science and Technology 48 3
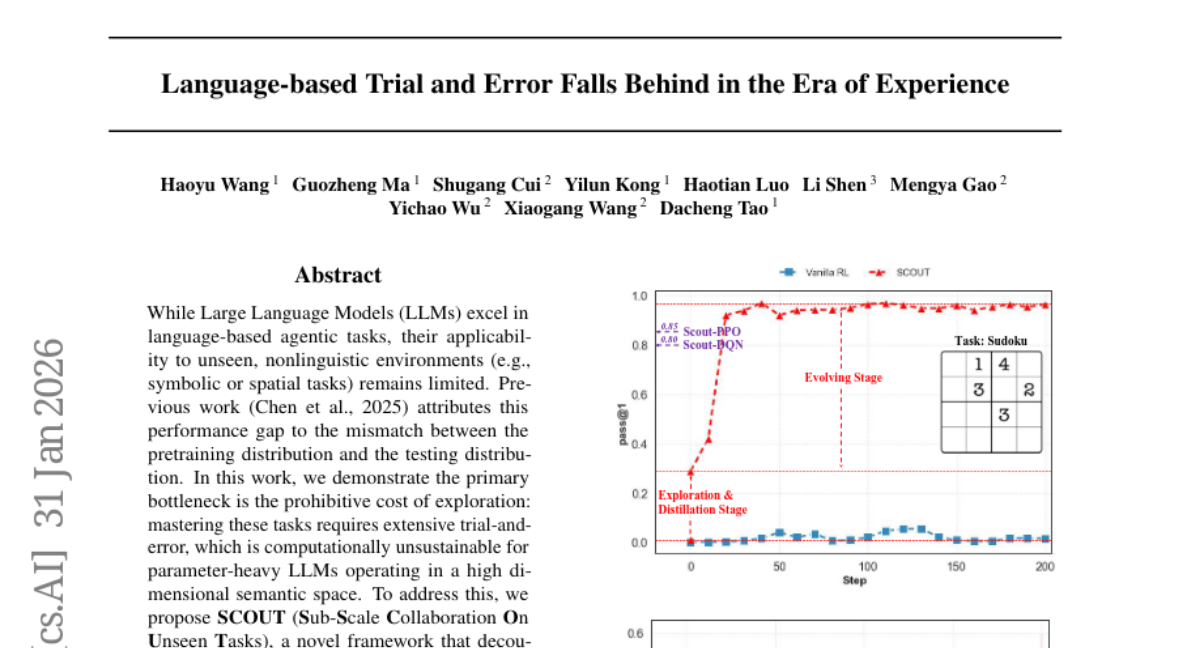
Submitted by LordNoah 15 Language-based Trial and Error Falls Behind in the Era of Experience Nanyang Technological University 8 3
Submitted by hba123 11 Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening · 4 authors 11
Submitted by EnyiJiang 10 Latent Adversarial Regularization for Offline Preference Optimization Stanford University 1 2
Submitted by taesiri 10 Self-Improving Pretraining: using post-trained models to pretrain better models Meta Research 3
Submitted by zhuoranyang 10 Llama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report Cisco Foundation AI 3
Submitted by kunato 9 Typhoon-S: Minimal Open Post-Training for Sovereign Large Language Models Typhoon 7 4
Submitted by chen-yingfa 7 Hybrid Linear Attention Done Right: Efficient Distillation and Effective Architectures for Extremely Long Contexts OpenBMB 5 4
Submitted by yiboowang 7 VTC-R1: Vision-Text Compression for Efficient Long-Context Reasoning Nanyang Technological University 15 3
Submitted by topyun 7 MAD: Modality-Adaptive Decoding for Mitigating Cross-Modal Hallucinations in Multimodal Large Language Models · 4 authors 3
Submitted by taesiri 7 DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents Google 3
Submitted by zz1358m 6 Beyond Imitation: Reinforcement Learning for Active Latent Planning · 2 authors 3
Submitted by WuyangZzzz 5 KromHC: Manifold-Constrained Hyper-Connections with Kronecker-Product Residual Matrices · 4 authors 3 5
Submitted by stefan-it 4 FineInstructions: Scaling Synthetic Instructions to Pre-Training Scale FineInstructions 5
Submitted by bruiiii 3 MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources · 8 authors 67 3
Submitted by JianhuiChen 3 Mechanistic Data Attribution: Tracing the Training Origins of Interpretable LLM Units Peking University 2 4
Submitted by Sugewud 3 Generation Enhances Understanding in Unified Multimodal Models via Multi-Representation Generation · 7 authors 10 4
Submitted by robinzixuan 2 FROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning Northwestern University 3
Submitted by micahr234 1 Reinforcement Learning from Meta-Evaluation: Aligning Language Models Without Ground-Truth Labels · 2 authors 3
Submitted by DarshanDeshpande 1 Benchmarking Reward Hack Detection in Code Environments via Contrastive Analysis Patronus AI 2
Submitted by Baran47 1 Flow-based Extremal Mathematical Structure Discovery Center for Scalable Data Analytics and Artificial Intelligence Dresden/Leipzig 3
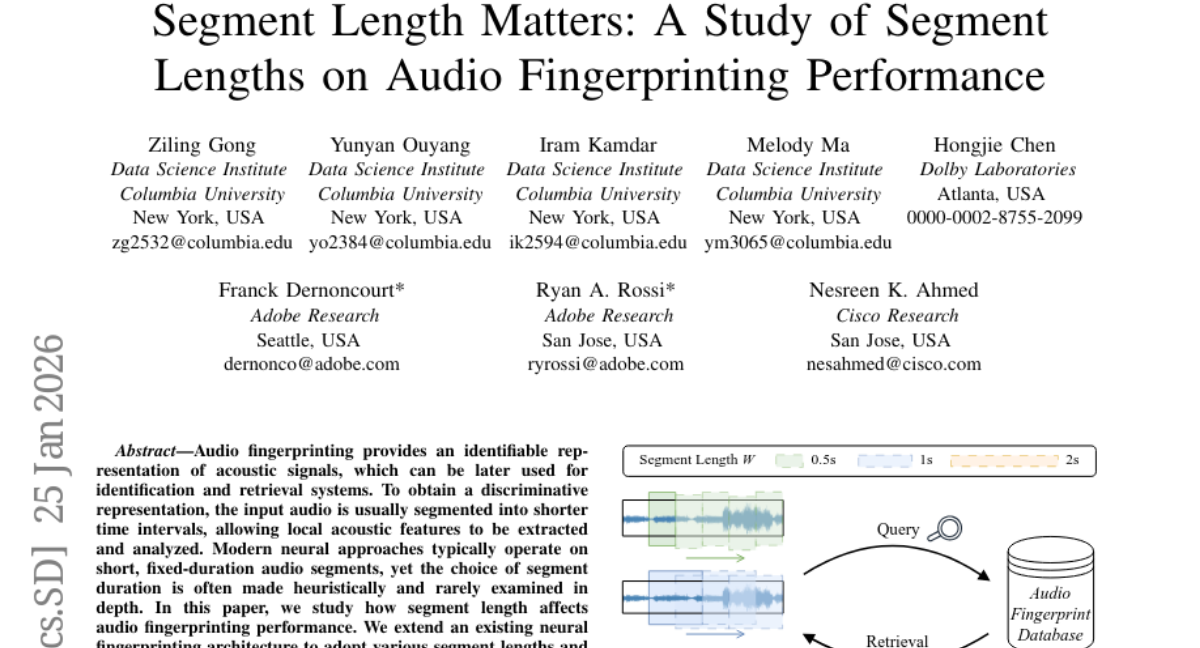
Submitted by Franck-Dernoncourt 1 Segment Length Matters: A Study of Segment Lengths on Audio Fingerprinting Performance · 8 authors 2
Submitted by Franck-Dernoncourt 1 PRISM: Learning Design Knowledge from Data for Stylistic Design Improvement · 5 authors 2
Submitted by ZYao720 - WebArbiter: A Principle-Guided Reasoning Process Reward Model for Web Agents Ludwig Maximilian University of Munich 2
Submitted by Beegbrain - Spotlighting Task-Relevant Features: Object-Centric Representations for Better Generalization in Robotic Manipulation · 4 authors 2
Submitted by taesiri - WorldBench: Disambiguating Physics for Diagnostic Evaluation of World Models · 10 authors 2
Submitted by Beegbrain - STORM: Slot-based Task-aware Object-centric Representation for robotic Manipulation · 3 authors 2


 Wendy-Fly
Wendy-Fly