
Quantum Assistant
Collection
Multimodal data and models for Quantum Computing with Qiskit
•
12 items
•
Updated
![]()
The first multimodal Vision-Language Model specialized for quantum computing with Qiskit
This model is a fine-tuned version of Qwen3-VL-8B-Instruct specialized for quantum computing tasks using Qiskit 2.0. This model can interpret visual representations of quantum computing: circuit diagrams, Bloch spheres, and measurement histograms.
The model was trained using Rank-Stabilized Low-Rank Adaptation (rsLoRA) with rank 64 for 1 epoch on the Quantum Assistant Dataset, achieving significant improvements on multimodal quantum code generation tasks.
Evaluation was conducted on three complementary benchmarks: Qiskit HumanEval (151 function completion problems), Qiskit HumanEval Hard (151 code generation problems), and the synthetic test set (1,290 samples). Models were served via vLLM on A100 80GB PCIe with greedy decoding (temperature 0).
| Model | Qiskit HumanEval | Synthetic Dataset | |||||
|---|---|---|---|---|---|---|---|
| QHE | QHE Hard | Func. Compl. | Code Gen. | QA | Text | Multimodal | |
| Fine-tuned | |||||||
| Qwen3-VL-FT (r32, 2ep) | 43.71% | 28.48% | 56.96% | 44.36% | 38.02% | 45.45% | 63.39% |
| Qwen3-VL-FT (r32, 1ep) | 40.40% | 29.14% | 51.55% | 41.91% | 37.31% | 42.49% | 57.14% |
| Qwen3-VL-FT (r64, 1ep) | 38.41% | 22.52% | 52.84% | 42.89% | 38.24% | 42.66% | 60.71% |
| Specialized (IBM) | |||||||
| Qwen2.5-Coder-14B-Qiskit† | 49.01% | 25.17% | 47.48% | 25.51% | 19.46% | 36.19% | — |
| Baseline | |||||||
| Qwen3-VL-8B-Instruct | 32.45% | 11.92% | 38.92% | 25.98% | 20.66% | 30.24% | 37.50% |
| InternVL3.5-8B-MPO | 20.53% | 9.27% | 32.47% | 19.61% | 25.81% | 21.85% | 36.16% |
| Ministral-3-8B-Instruct-2512 | 17.88% | 11.26% | 29.12% | 21.81% | 20.50% | 20.98% | 36.61% |
QHE: Qiskit HumanEval (function completion) · QHE Hard: code generation · †Qwen2.5-Coder-14B-Qiskit evaluated only on text samples (55% of synthetic dataset)
| Metric | Improvement vs Baseline |
|---|---|
| Qiskit HumanEval Pass@1 | +11.26 pp (32.45% → 43.71%) |
| Qiskit HumanEval Hard Pass@1 | +16.56 pp (11.92% → 28.48%) |
| Multimodal Code Pass@1 | +25.89 pp (37.50% → 63.39%) |
| Text-only Code Pass@1 | +15.21 pp (30.24% → 45.45%) |
The most significant differential is in multimodal samples: the fine-tuned model achieves 63.39% Pass@1 on image-based code generation vs 45.45% on text-only (+17.94 pp), validating that training on visual-textual samples develops domain-specific visual understanding capabilities.
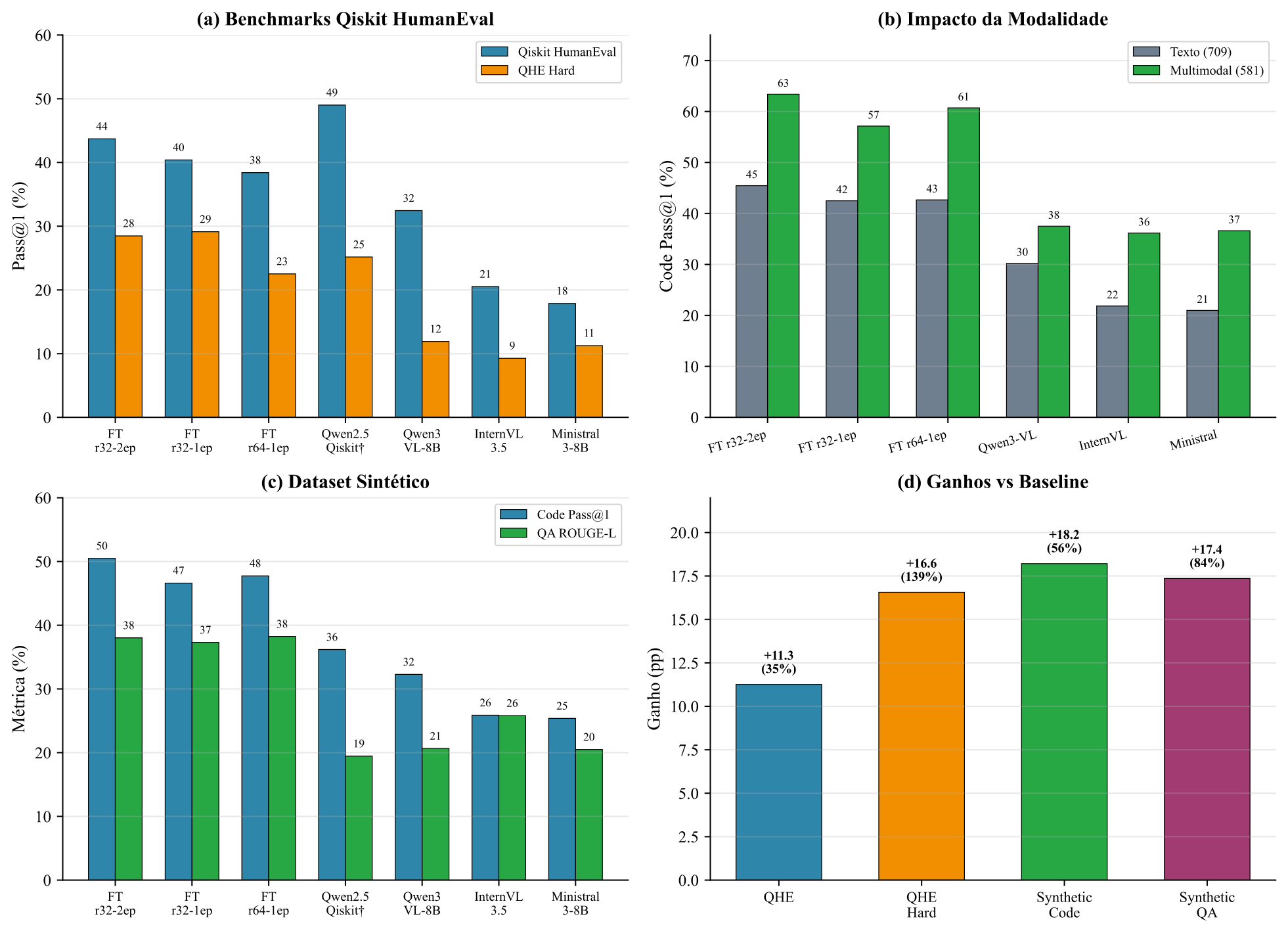
Evaluation results: (a) Qiskit HumanEval benchmarks, (b) visual content impact, (c) synthetic dataset, (d) fine-tuning gains
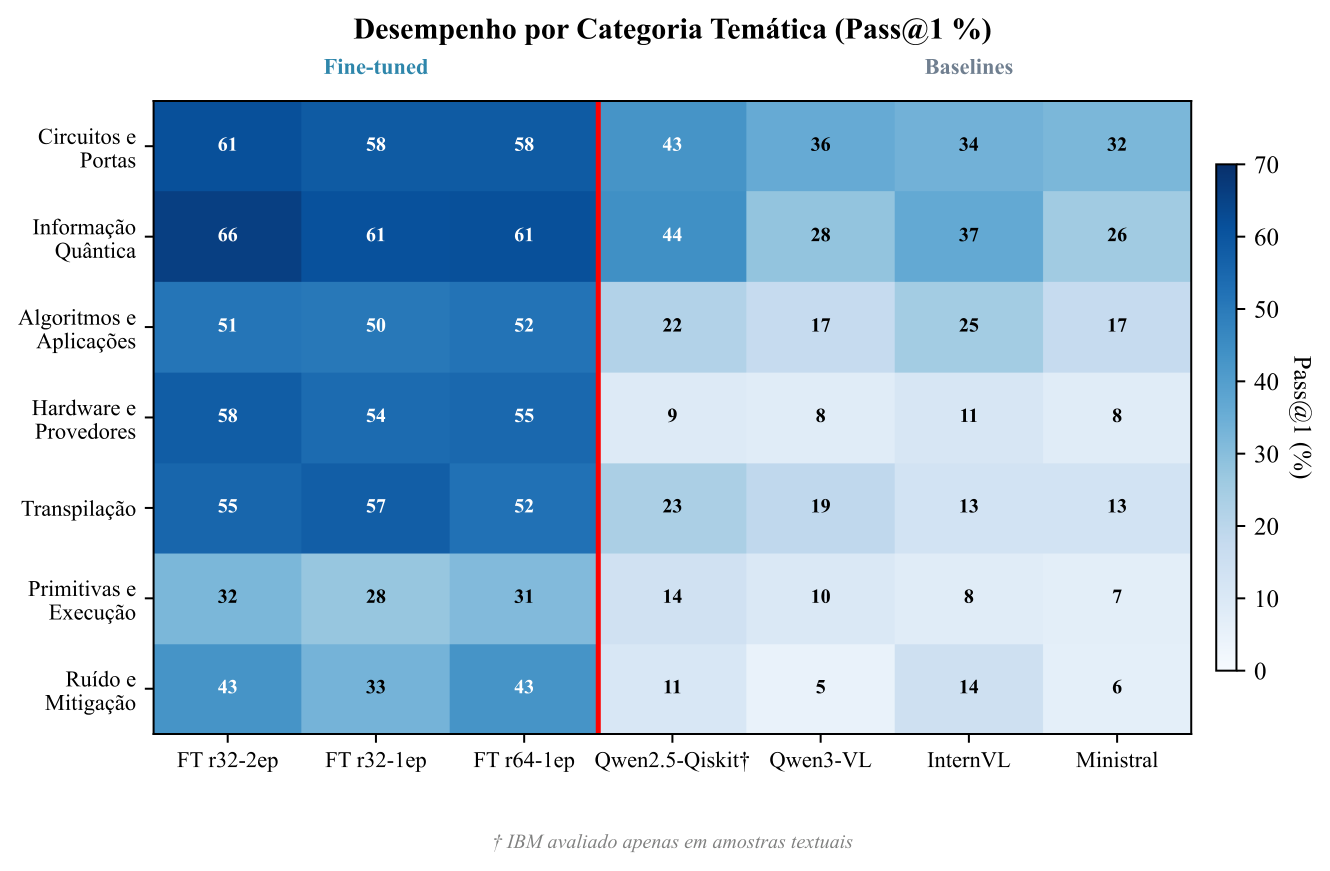
Performance heatmap by thematic category (Pass@1 %). Red line separates fine-tuned models (left) from baselines (right)
| Category | Pass@1 | vs Baseline |
|---|---|---|
| quantum_info_and_operators | 65.76% | +37.74 pp |
| circuits_and_gates | 61.47% | +25.46 pp |
| hardware_and_providers | 57.94% | +50.00 pp |
| transpilation_and_compilation | 57.43% | +38.62 pp |
| algorithms_and_applications | 52.27% | +28.18 pp |
| noise_and_error_mitigation | 42.86% | +38.10 pp |
| primitives_and_execution | 32.18% | +21.84 pp |
The experimental strategy was organized in two phases: PEFT technique selection and hyperparameter optimization.
Five LoRA variants were compared with controlled configuration (r=16, α=32, 1 epoch):
| Variant | Eval Loss ↓ | Eval Accuracy ↑ | Runtime (s) |
|---|---|---|---|
| rsLoRA | 0.622 | 0.818 | 1,060 |
| DoRA | 0.622 | 0.818 | 2,307 |
| rsLoRA (frozen aligner) | 0.623 | 0.817 | 1,057 |
| LoRA (vanilla) | 0.646 | 0.812 | 1,056 |
| PiSSA | 0.657 | 0.812 | 1,172 |
| OLoRA | 0.742 | 0.794 | 1,067 |
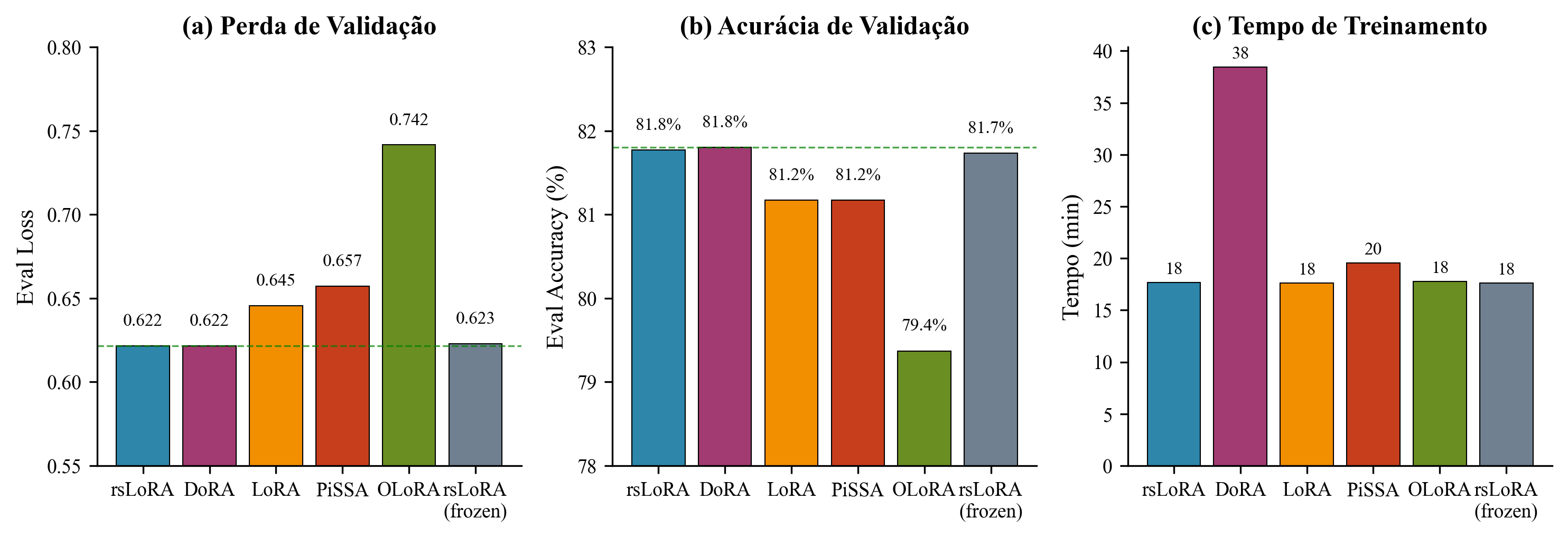
Comparison of PEFT variants: (a) validation loss, (b) token accuracy, (c) training time
Key findings:
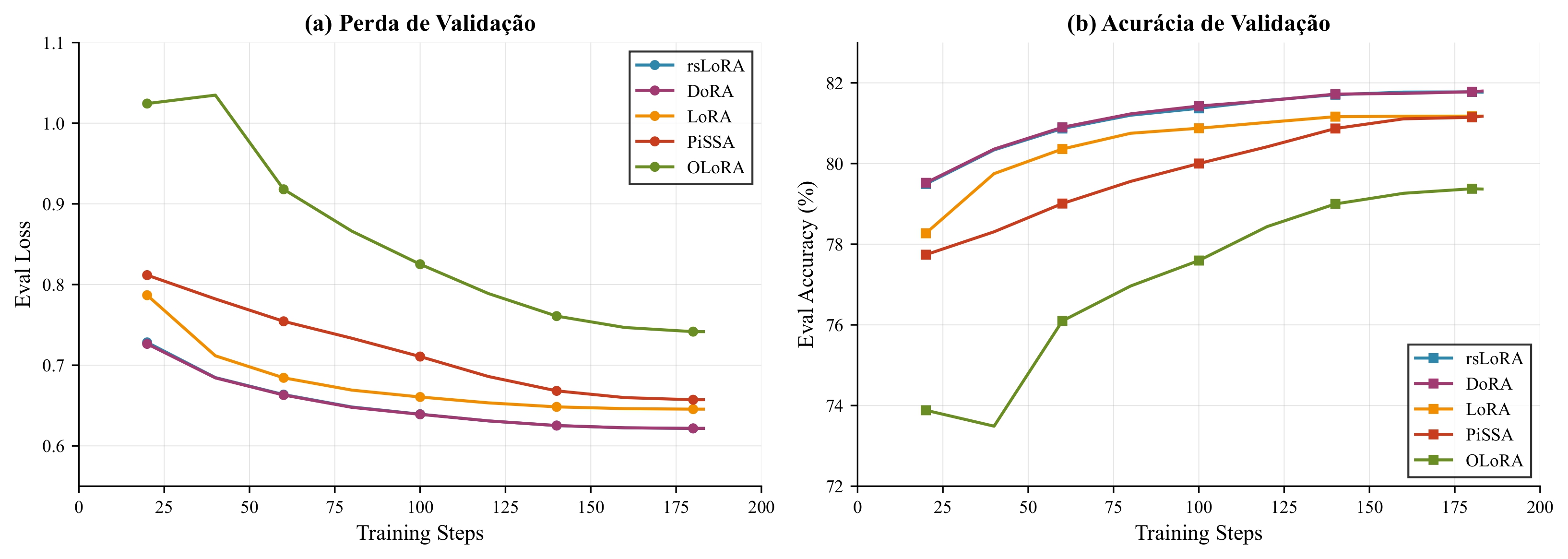
Convergence curves of validation loss for PEFT variants
With rsLoRA selected, the impact of adapter rank and training duration was investigated:
| Configuration | Eval Loss ↓ | Eval Accuracy ↑ | Notes |
|---|---|---|---|
| r=32, 1 epoch | 0.607 | 0.821 | Optimal trade-off |
| r=64, 1 epoch | 0.609 | 0.822 | Marginal improvement |
| r=16, 1 epoch | 0.622 | 0.818 | Baseline rsLoRA |
| r=32, 2 epochs | 0.638 | 0.825 | Slight overfitting |
| r=128, 3 epochs | 0.789 | 0.822 | Severe overfitting |
![]()
Impact of adapter rank on validation loss
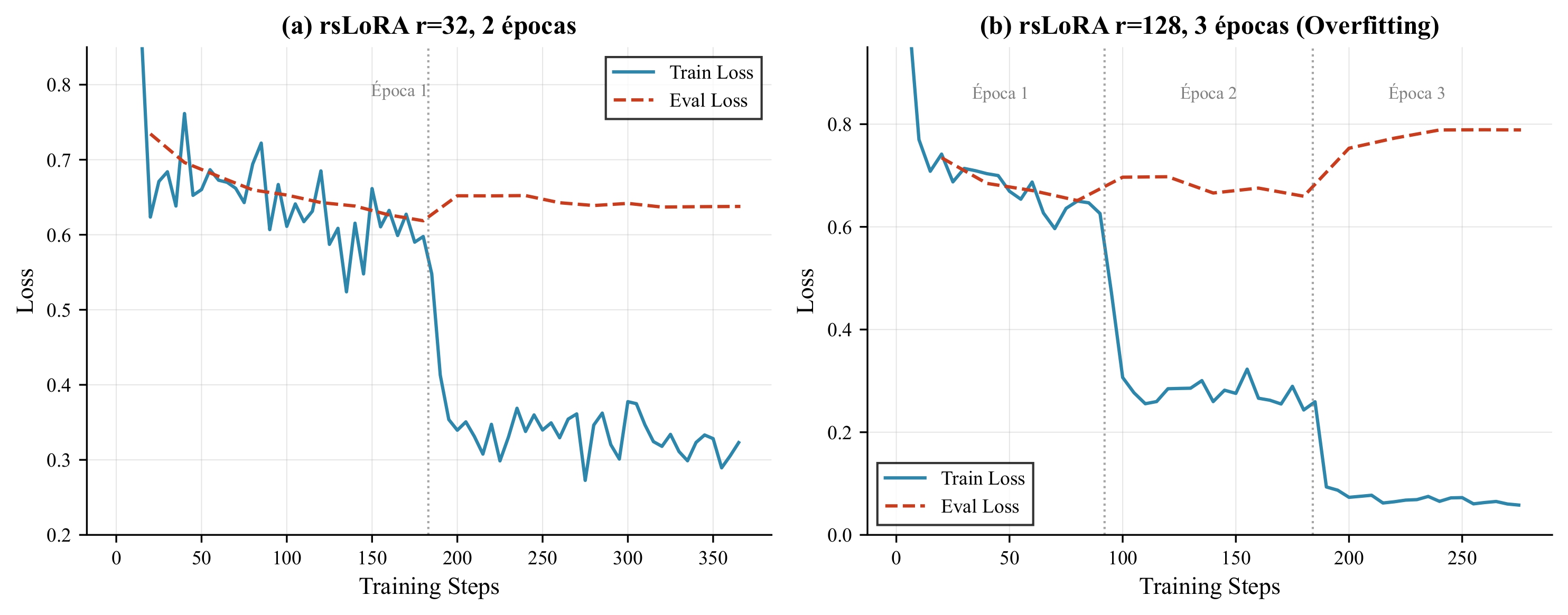
Overfitting analysis: (a) r32-2ep configuration, (b) r128-3ep configuration
Conclusions: rsLoRA with r=32 and 1-2 epochs maximizes generalization while avoiding memorization of the synthetic dataset.
This model is part of the Quantum Assistant collection. All models are merged versions ready for inference:
| Model | Configuration | Description |
|---|---|---|
| Qwen3-VL-8B-rslora-r32-2 | rsLoRA r=32, 2 epochs | Best overall performance |
| Qwen3-VL-8B-rslora-r32 | rsLoRA r=32, 1 epoch | Best generalization |
| Qwen3-VL-8B-rslora-r64 | rsLoRA r=64, 1 epoch | Higher capacity |
| Qwen3-VL-8B-rslora-r128 | rsLoRA r=128, 1 epoch | Maximum capacity |
| Qwen3-VL-8B-lora | LoRA r=16, 1 epoch | Vanilla LoRA |
| Qwen3-VL-8B-dora | DoRA r=16, 1 epoch | Magnitude-direction decomposition |
| Qwen3-VL-8B-pissa | PiSSA r=16, 1 epoch | SVD initialization |
| Qwen3-VL-8B-olora | OLoRA r=16, 1 epoch | QR orthonormal initialization |
| Qwen3-VL-8B-rslora-frozen | rsLoRA r=16, frozen aligner | Ablation study |
| Qwen3-VL-8B-rslora | rsLoRA r=16, 1 epoch | Baseline rsLoRA |
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8000 \
--model samuellimabraz/Qwen3-VL-8B-rslora-r64 \
--gpu-memory-utilization 0.92 \
--max-model-len 12288 \
--max-num-seqs 16 \
--max-num-batched-tokens 49152 \
--enable-chunked-prefill \
--enable-prefix-caching
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
model = Qwen3VLForConditionalGeneration.from_pretrained(
"samuellimabraz/Qwen3-VL-8B-rslora-r64",
torch_dtype="auto",
device_map="auto"
)
processor = AutoProcessor.from_pretrained("samuellimabraz/Qwen3-VL-8B-rslora-r64")
messages = [
{"role": "system", "content": "You are a quantum computing expert assistant specializing in Qiskit."},
{"role": "user", "content": "Create a function that builds a 3-qubit GHZ state and returns the circuit."}
]
messages_with_image = [
{"role": "system", "content": "You are a quantum computing expert assistant specializing in Qiskit."},
{"role": "user", "content": [
{"type": "image", "image": "path/to/circuit.png"},
{"type": "text", "text": "Implement the quantum circuit shown in the image."}
]}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=1024)
output = processor.batch_decode(
generated_ids[:, inputs.input_ids.shape[1]:],
skip_special_tokens=True
)[0]
print(output)
| Parameter | Value |
|---|---|
| Base Model | Qwen/Qwen3-VL-8B-Instruct |
| PEFT Method | rsLoRA (Rank-Stabilized LoRA) |
| Rank (r) | 64 |
| Alpha (α) | 128 |
| Dropout | 0.10 |
| Target Modules | all-linear |
| Learning Rate | 2e-4 |
| LR Scheduler | Cosine |
| Weight Decay | 0.05 |
| Warmup Steps | 10 |
| Epochs | 1 |
| Batch Size | 32 |
| Precision | bfloat16 |
| Framework | ms-swift |
| Component | Status |
|---|---|
| Vision Encoder (ViT) | ❄️ Frozen |
| Vision-Language Aligner | 🔥 Trainable |
| Language Model (LLM) | 🔥 Trainable |
You are a quantum computing expert assistant specializing in Qiskit.
Provide accurate, clear, and well-structured responses about quantum computing concepts,
algorithms, and code implementation. Use Qiskit 2.0 best practices.
circuits_and_gates than primitives_and_executionIf you use this model in your research, please cite:
@misc{braz2025quantumassistant,
title={Quantum Assistant: Especializa{\c{c}}{\~a}o de Modelos Multimodais para Computa{\c{c}}{\~a}o Qu{\^a}ntica},
author={Braz, Samuel Lima and Leite, Jo{\~a}o Paulo Reus Rodrigues},
year={2025},
institution={Universidade Federal de Itajub{\'a} (UNIFEI)},
url={https://github.com/samuellimabraz/quantum-assistant}
}
This model is released under the Apache 2.0 License.
Base model
Qwen/Qwen3-VL-8B-Instruct